Chatbot
About the project:
Alright so this isn't exactly a "chatbot" in the classical sense (it's no ELIZA), but it does use a lot of the same principles. Essentially, text is fed in via some external, specified text file. The text is then analyzed, sorted, and saved into a json file as a sort of Markov Chain. This Markov Chain can then be used to generate random strings of specified lengths, based on user input.
How to use:
Learning:
To "learn" from a file (or user input), do the following...
- Download a text file into the folder holding the chatbot project
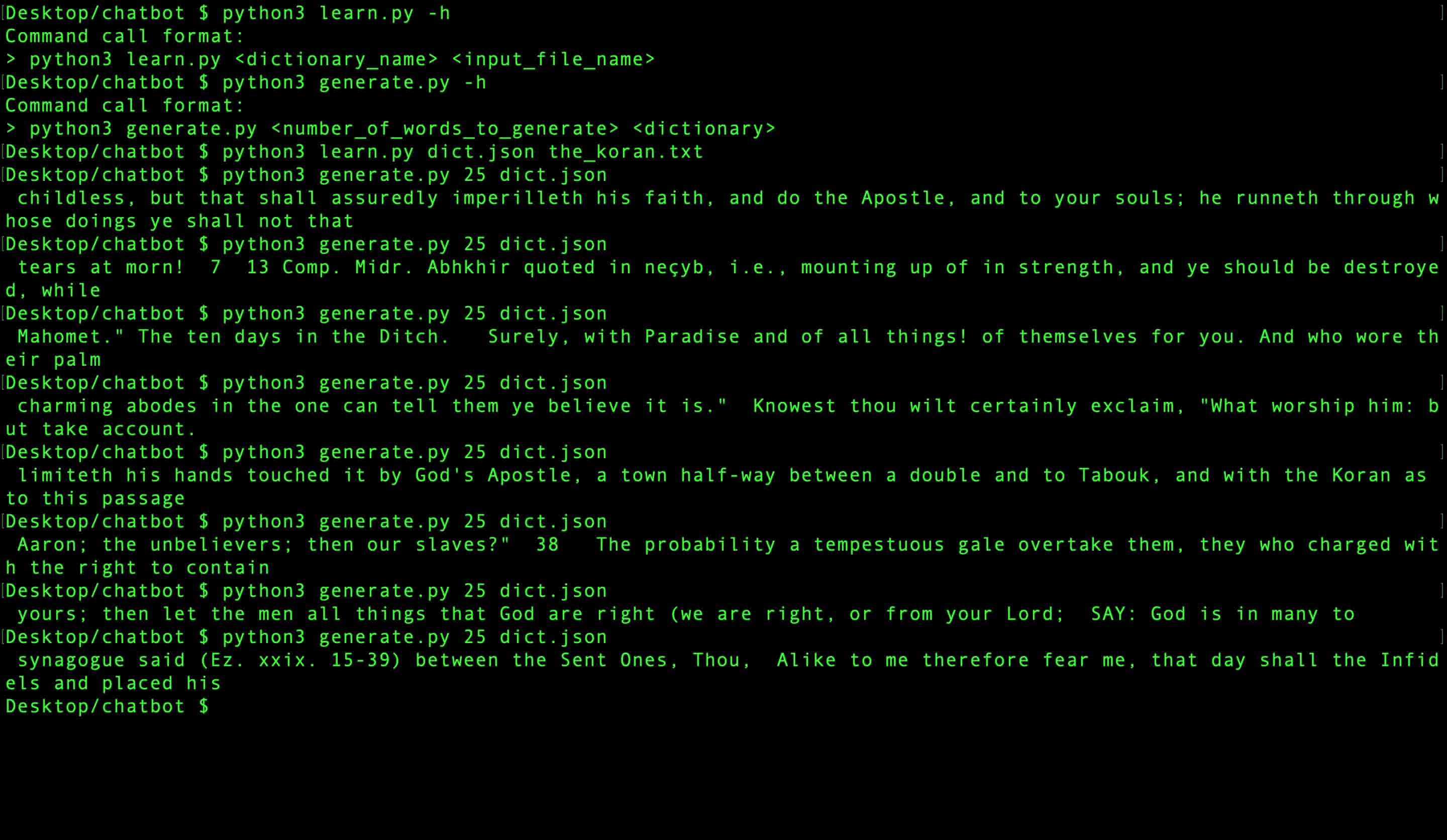
- Run the following command:
python3 learn.py <dictionary_name> <input_file_name>- dictionary_name : json file to store the markov chain in (defaults to dict.json)
- input_name : document to learn from (defaults to interactive mode, where you type in text rather than reading it from a file)
Generating:
To generate text based on a previously created Markov Chain json file, do the following:
- Ensure the json dictionary you will use is in the same folder holding the chatbot project
- Run the following command:
python3 generate.py <n> <d>- n : Number of words to generate for our output string
- d : Dictionary name holding the associated json file with the Markov Chain
Improvements:
This project is more like a baseline to a larger project since it can really be vastly improved on. Here are just a few of the ways I have thought on how to improve this.- TweetBot: On the command line, the user could give someone's Twitter handle. Then, the tool would use Twitters api to create a text file consisting of the body of all of that user's tweets. Then, that file would be fed in to the "generate" function of the project, where it would create a random tweet (of specified and appropriate length) that is built based off the words used in the given person's actual tweets.
- Word Types: If I implemented this I'd like to study a bit of linguistics first. Basically, each word could be tagged as one of the eight English parts of speech. When generating sentences, we could have sentence "templates", (e.g. Start with pronoun, follow with a verb, and end with an adverb), we could have a certain number of each of the parts of speech required per sentence, we could ensure each has at least one verb and one noun (to make it a legitimate english sentence), or do a mix of any number of these.
- Sentence Beginners/Enders: I think this could be an easy way to make more coherent and realistic sentences. When learning from text, the algorithm could mark words if they're first or last in a sentence. Then, when generating sentences, normalize the chance of a first or last word in a generated sentence proportional to how often it began/concluded sentences in the text that it learned from.
Source Code:
- You can find all the code here.
- Note: Most of the idea for this project came from this video. Feel free to give it a watch and check out the channel, it's pretty awesome!
Created: ~06/26/2020
Last Updated: ~06/26/2020
Last Updated: ~06/26/2020